You don't Have to Be A big Company To start Deepseek

본문
Chinese drop of the apparently (wildly) cheaper, less compute-hungry, less environmentally insulting DeepSeek AI chatbot, thus far few have thought-about what this means for AI’s affect on the arts. Based in Hangzhou, Zhejiang, it's owned and funded by the Chinese hedge fund High-Flyer. A span-extraction dataset for Chinese machine reading comprehension. DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs. On FRAMES, a benchmark requiring query-answering over 100k token contexts, DeepSeek-V3 closely trails GPT-4o while outperforming all different models by a big margin. On Arena-Hard, DeepSeek-V3 achieves an impressive win rate of over 86% against the baseline GPT-4-0314, performing on par with high-tier models like Claude-Sonnet-3.5-1022. Comprehensive evaluations demonstrate that DeepSeek-V3 has emerged as the strongest open-supply mannequin at the moment available, and achieves performance comparable to leading closed-supply fashions like GPT-4o and Claude-3.5-Sonnet. In algorithmic tasks, DeepSeek-V3 demonstrates superior efficiency, outperforming all baselines on benchmarks like HumanEval-Mul and LiveCodeBench. In domains the place verification through external instruments is straightforward, similar to some coding or mathematics eventualities, RL demonstrates distinctive efficacy. The controls have pressured researchers in China to get inventive with a wide range of instruments which might be freely accessible on the internet. Local fashions are additionally better than the large industrial fashions for sure sorts of code completion tasks.
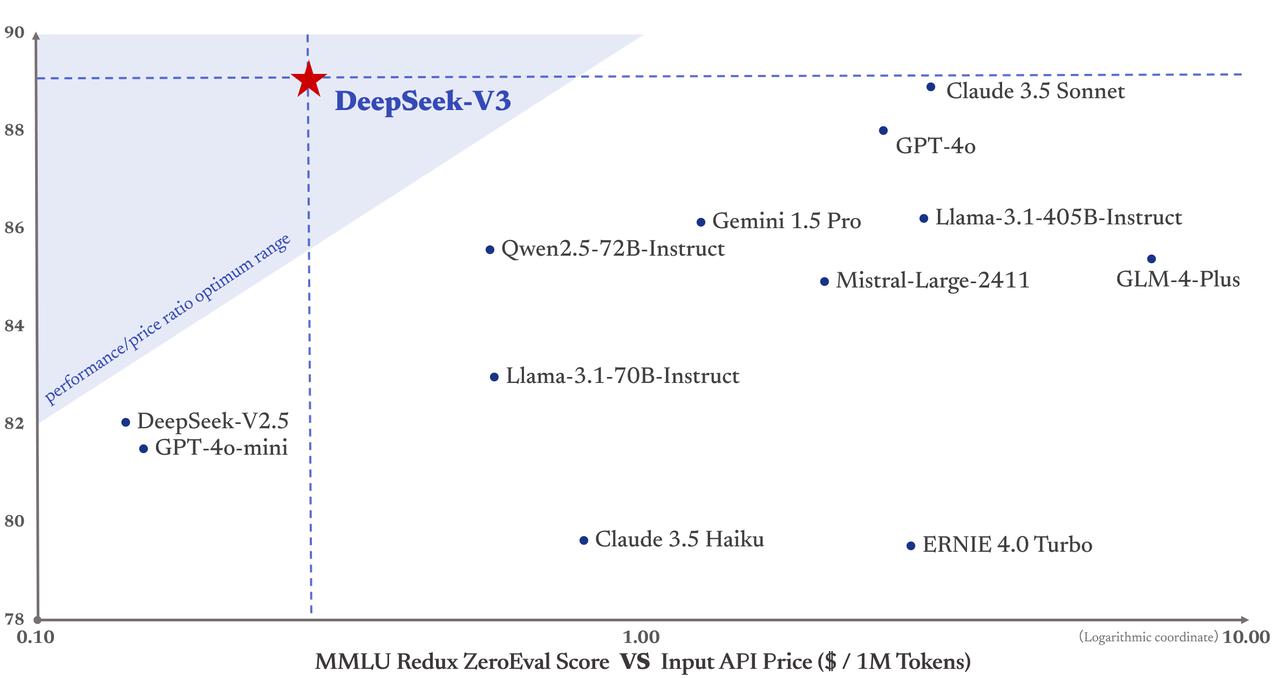 This demonstrates the robust capability of DeepSeek-V3 in dealing with extremely lengthy-context tasks. DeepSeek-V3 demonstrates aggressive efficiency, standing on par with prime-tier fashions resembling LLaMA-3.1-405B, GPT-4o, and Claude-Sonnet 3.5, whereas significantly outperforming Qwen2.5 72B. Moreover, DeepSeek r1-V3 excels in MMLU-Pro, a extra challenging educational information benchmark, the place it intently trails Claude-Sonnet 3.5. On MMLU-Redux, a refined model of MMLU with corrected labels, DeepSeek-V3 surpasses its friends. The publish-coaching also makes successful in distilling the reasoning functionality from the DeepSeek-R1 collection of models. LongBench v2: Towards deeper understanding and reasoning on realistic lengthy-context multitasks. The lengthy-context capability of DeepSeek-V3 is additional validated by its best-in-class performance on LongBench v2, a dataset that was released only a few weeks before the launch of DeepSeek V3. We use CoT and non-CoT strategies to judge mannequin efficiency on LiveCodeBench, where the info are collected from August 2024 to November 2024. The Codeforces dataset is measured using the share of competitors. As well as to straightforward benchmarks, we additionally evaluate our fashions on open-ended generation duties utilizing LLMs as judges, with the outcomes proven in Table 7. Specifically, we adhere to the unique configurations of AlpacaEval 2.0 (Dubois et al., 2024) and Arena-Hard (Li et al., 2024a), which leverage GPT-4-Turbo-1106 as judges for pairwise comparisons.
This demonstrates the robust capability of DeepSeek-V3 in dealing with extremely lengthy-context tasks. DeepSeek-V3 demonstrates aggressive efficiency, standing on par with prime-tier fashions resembling LLaMA-3.1-405B, GPT-4o, and Claude-Sonnet 3.5, whereas significantly outperforming Qwen2.5 72B. Moreover, DeepSeek r1-V3 excels in MMLU-Pro, a extra challenging educational information benchmark, the place it intently trails Claude-Sonnet 3.5. On MMLU-Redux, a refined model of MMLU with corrected labels, DeepSeek-V3 surpasses its friends. The publish-coaching also makes successful in distilling the reasoning functionality from the DeepSeek-R1 collection of models. LongBench v2: Towards deeper understanding and reasoning on realistic lengthy-context multitasks. The lengthy-context capability of DeepSeek-V3 is additional validated by its best-in-class performance on LongBench v2, a dataset that was released only a few weeks before the launch of DeepSeek V3. We use CoT and non-CoT strategies to judge mannequin efficiency on LiveCodeBench, where the info are collected from August 2024 to November 2024. The Codeforces dataset is measured using the share of competitors. As well as to straightforward benchmarks, we additionally evaluate our fashions on open-ended generation duties utilizing LLMs as judges, with the outcomes proven in Table 7. Specifically, we adhere to the unique configurations of AlpacaEval 2.0 (Dubois et al., 2024) and Arena-Hard (Li et al., 2024a), which leverage GPT-4-Turbo-1106 as judges for pairwise comparisons.
In addition to the MLA and DeepSeekMoE architectures, it additionally pioneers an auxiliary-loss-free technique for load balancing and sets a multi-token prediction coaching goal for stronger performance. Similarly, DeepSeek-V3 showcases exceptional efficiency on AlpacaEval 2.0, outperforming each closed-source and open-source fashions. Our research means that data distillation from reasoning models presents a promising path for post-coaching optimization. PIQA: reasoning about physical commonsense in pure language. • We will persistently explore and iterate on the deep pondering capabilities of our models, aiming to boost their intelligence and drawback-solving talents by expanding their reasoning length and depth. • We are going to persistently research and refine our model architectures, aiming to further improve each the training and inference efficiency, striving to approach efficient assist for infinite context length. We'll keep extending the documentation however would love to hear your enter on how make faster progress towards a more impactful and fairer analysis benchmark! These eventualities will be solved with switching to Symflower Coverage as a better coverage kind in an upcoming model of the eval. In conclusion, the details help the concept a rich particular person is entitled to higher medical companies if she or he pays a premium for them, as that is a standard function of market-based healthcare systems and is in line with the principle of particular person property rights and client alternative.
Subscribe without cost to obtain new posts and help my work. A helpful resolution for anyone needing to work with and preview JSON data efficiently. Whereas I did not see a single reply discussing how you can do the actual work. More than a year in the past, we revealed a weblog publish discussing the effectiveness of using GitHub Copilot in combination with Sigasi (see unique publish). I say recursive, you see recursive. I feel you’ll see possibly more concentration in the new year of, okay, let’s not actually worry about getting AGI here. However, in additional normal scenarios, constructing a suggestions mechanism by way of onerous coding is impractical. We consider that this paradigm, which combines supplementary info with LLMs as a suggestions source, is of paramount significance. The LLM serves as a versatile processor capable of reworking unstructured info from numerous eventualities into rewards, in the end facilitating the self-enchancment of LLMs. Censorship regulation and implementation in China’s main models have been efficient in limiting the vary of attainable outputs of the LLMs without suffocating their capability to reply open-ended questions. In line with DeepSeek’s inside benchmark testing, DeepSeek V3 outperforms both downloadable, "openly" accessible models and "closed" AI fashions that can solely be accessed by way of an API.
댓글목록0